

Unlocking the Power of Elixir's Enumerables

Looking forward to learn through teaching, building and sharing!
Dealing with data structures is at the core of any programming activity and high-level languages like Elixir provide well-structured constructs in the standard library to easily work with them.
In this post, we'll go through how the Enum and Stream modules work with data types like List, Map and Stream through the use of the Enumerable and Collectable protocols to provide a batteries-included system that can also be reused and extended for other data structures.
High-level overview
To understand how all the pieces work together we first need to define which those pieces are:
Enumerables: Technically speaking these are any data type that implements the
Enumerableprotocol. We can think of them as collections that share a common way of being accessed.EnumandStreamutility modules: Group functions to interact with enumerables mainly through theEnumerableandCollectableprotocols. They have clear tradeoffs that lead to module separation.List,Map,Streamdata structures: These are the modules defining the data types and the specific functions to work with them.
From here we can organize these abstractions by separating which modules use the enumerable via protocol functions and which types implement the protocol.
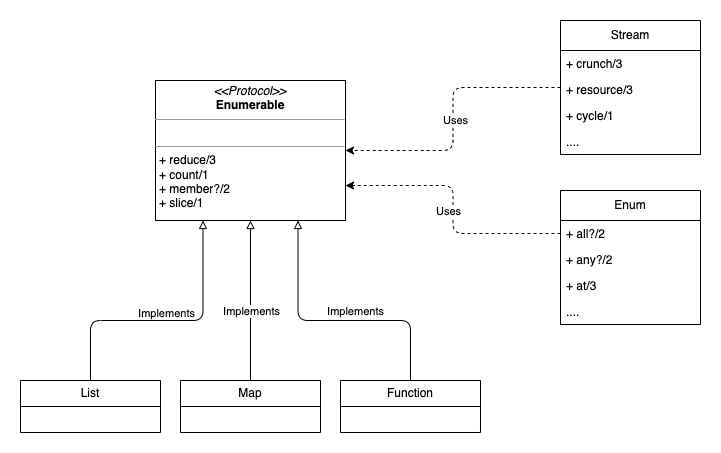
Here we can see in the diagram how Stream and Enum utility functions don't access the types (List, Map, Function, etc) directly when dealing with them. This separation helps achieve two key extensibility benefits:
Utility functions can be reused by any
Enumerable: Which means they don't need to know more about the data type than what the protocol requires.Any data type can implement the
Enumerableprotocol to be reusable by the Utility functions.
In general, protocols were designed to achieve this separation and reusability. That means the Collectable protocol, which deals with traversing the data structure, also has similar separations and benefits.
But protocols don't need to live in isolation from each other. Enumerable and Collectable relation is well explained in the docs. Here's an extract of the core parts:
The
Enumerableprotocol is useful to take values out of a collection. To support a wide range of values, the functions provided by theEnumerableprotocol do not keep shape. It was designed to support infinite collections, resources and other structures with fixed shape.The
Collectablemodule was designed to fill the gap left by theEnumerableprotocol. If the functions inEnumerableare about taking values out, then aCollectableis about collecting those values into a structure.
To learn more about which modules implement the Enumerable protocol we can run iex -S mix from our mix project and the:
iex> Enumerable.__protocol__(:impls)
{:consolidated,
[Date.Range, File.Stream, Function, GenEvent.Stream, HashDict, HashSet,
IO.Stream, List, Map, MapSet, Range, Stream]}
iex> Collectable.__protocol__(:impls)
{:consolidated,
[BitString, File.Stream, HashDict, HashSet, IO.Stream, List, Map, MapSet,
Mix.Shell]}
Now that we have a general understanding of the organization of enumerables we can continue with the main modules used to interact with them (besides their own module functions).
Enum and Stream
Elixir defines these two modules with functions to work with enumerables and collectables interchangeably most of the time. The key difference lies in the way functions return results.
Enum: focuses on eager operations. This means most functions included in this module will process the collection and return the final result right away.Stream: operations are lazy, allowing processing functions to get chained together to process each element as needed.
Enum: Eager operations
To better understand what eagerness implies here's a simple example with calls to Enum functions linked together with pipe operators.
result = 1..100_000
|> Enum.map(fn item -> item * 10 end)
|> Enum.filter(fn item -> item > 10 end)
|> Enum.map(fn item -> (item + 3) / 2 end)
|> Enum.reduce(fn item, acc -> acc + item end)
|> dbg()
Each function operates on the result of the previous call which holds the final computed result for the intermedia operation.
By appending dbg/0 at the end of the pipe we can see how these intermediate lists are created.
1..100_000 #=> 1..100000
|> Enum.map(fn item -> item * 10 end) #=> [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170,
180, 190, 200, 210, 220, 230, 240, 250, 260, 270, 280, 290, 300, 310, 320, 330,
340, 350, 360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470, 480, 490,
500, ...]
|> Enum.filter(fn item -> item > 10 end) #=> [20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180,
190, 200, 210, 220, 230, 240, 250, 260, 270, 280, 290, 300, 310, 320, 330, 340,
350, 360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470, 480, 490, 500,
510, ...]
|> Enum.map(fn item -> (item + 3) / 2 end) #=> [11.5, 16.5, 21.5, 26.5, 31.5, 36.5, 41.5, 46.5, 51.5, 56.5, 61.5, 66.5, 71.5,
76.5, 81.5, 86.5, 91.5, 96.5, 101.5, 106.5, 111.5, 116.5, 121.5, 126.5, 131.5,
136.5, 141.5, 146.5, 151.5, 156.5, 161.5, 166.5, 171.5, 176.5, 181.5, 186.5,
191.5, 196.5, 201.5, 206.5, 211.5, 216.5, 221.5, 226.5, 231.5, 236.5, 241.5,
246.5, 251.5, 256.5, ...]
|> Enum.reduce(fn item, acc -> acc + item end) #=> 25000399993.5
Now imagine having to deal with collections of millions of records. From there is easy to imagine how working with large lists and multiple eager calls can lead to high memory usage. And even more on multitenant systems.
A good rule of thumb when working with Enum is: Use it by default unless you know you'll deal with very large collections or memory consumption gets affected by the way long pipelines transform data. In that case, profile your application and evaluate how using lazy operations via the Stream module functions behave.
For a complete list of Enum functions please check the cheatshet and the module's docs.
Stream: lazy operations
Stream module functions are lazy and exist to solve some of the problems Enum creates due to its eager nature. Besides that it also provides other features not available in Enum like infinite collections.
To see the difference in action we'll take the previous Enumexample and rewrite it using Stream functions:
result = 1..100_000
|> Stream.map(fn item -> item * 10 end)
|> Stream.filter(fn item -> item > 10 end)
|> Stream.map(fn item -> (item + 3) / 2 end)
|> Enum.reduce(fn item, acc -> acc + item end)
|> dbg()
The final function needs to be an eager one (From the Enum module or Stream.run/1) to execute the stream.
The output of each pipe operation can be visualized here:
1..100_000 #=> 1..100000
|> Stream.map(fn item -> item * 10 end) #=> #Stream<[enum: 1..100000, funs: [#Function<48.53678557/1 in Stream.map/2>]]>
|> Stream.filter(fn item -> item > 10 end) #=> #Stream<[
enum: 1..100000,
funs: [#Function<48.53678557/1 in Stream.map/2>,
#Function<40.53678557/1 in Stream.filter/2>]
]>
|> Stream.map(fn item -> (item + 3) / 2 end) #=> #Stream<[
enum: 1..100000,
funs: [#Function<48.53678557/1 in Stream.map/2>,
#Function<40.53678557/1 in Stream.filter/2>,
#Function<48.53678557/1 in Stream.map/2>]
]>
|> Enum.reduce(fn item, acc -> acc + item end) #=> 25000399993.5
25000399993.5
We can see how there aren't any intermediate collection results on each pipe operation but we still get the same result as before. You probably noticed what is going on already so there's no need to explain that streams are like chainable functions that get executed (in order) for each element of the original enumerable 😉.
That's all very cool but Stream shines when it comes to:
Running a function concurrently on each element in an enumerable: By using
Task.async_stream/2,Task.Supervisor.async_stream/6orTask.Supervisor.async_stream_nolink/6depending on the application requirements.Need to emit a sequence of values from a resource: By using
Stream.iterate/2,Stream.resource/3,Stream.unfold/2and other we can compute or get values to create our stream.
For a complete list of functions please check the module's docs.
Use cases
When it comes to choosing when to use Enum vs Streams a good rule of thumb is start using Enum by default but evaluate Stream when collections are large and pipelines are long. Nevertheless, there are also cases where Stream is the best initial choice and we'll see 3 cases where they mostly are.
Case 1: File processing
A very common use case for Streams involves: reading a file, doing some processing per line and finally writing the results to another one.
orig_file = "/path/to/file"
dest_file = "/path/to/other/file"
File.stream!(orig_file)
|> Stream.map(&String.replace(&1, "#", "%"))
|> Stream.into(File.stream!(dest_file))
|> Stream.run()
We can use this template to process log files, jsonsd, csv, tsv an any other line-oriented file. File.stream!/3 also accepts modes to instruct the stream to uncompress or compress the stream which comes in very handy to deal with even larger files at the cost of CPU cycles.
Case 2: Processing enumerables concurrently
Sometimes our application can leverage concurrency by splitting operations and running them potentially in parallel. With streams, we can collect initial parameters into an enumerable and pass them to Task.async_stream/3 to let it process them.
["resource1", "resource2", "resource3"]
|> Task.async_stream(fn item ->
fetch(item)
end)
|> Enum.to_list()
Here it will process 3 resources and call fetch for each of them concurrently. The default max equals the number of online schedulers. Most of the time this can map 1:1 with the number of cores or virtual CPUs the hardware or VM has. Assuming this is running on a 2vCPU VM only 2 of them will run concurrently and the third will wait for its turn when one of the two running resources is complete. By default, it timeouts after 5 seconds and when that happens the process that spawned the tasks exits.
The beauty of this function lies in its simplicity and configurability where we can control the max concurrency, timeouts, processing order and what to do during timeouts. E.g.
1..100_000
|> Task.async_stream(fn item ->
process(item)
end,
ordered: false,
max_concurrenty: 1000,
timeout: 60_000,
on_timeout: :kill_task)
|> Stream.reject(fn
{:exit, _} -> false
_ -> true
end)
|> Enum.to_list()
The only difference with the original example is how the resulting list is wrapped to accommodate the :kill_task option. For this example, we filter out any non-error simulating caring only about the side effect but knowing how many errors happened. Depending on your needs you can adapt how to process them through Stream or Enum.
Case 3: Remote Resource as a stream
Sometimes we can find resources that can be easily abstracted as streams to allow callers to emit values as needed. For instance, here's a sample where we abstract a particular resource that offers simple sequential access.
Stream.resource(
fn -> %{url: "http://example.com/some/resource", index: 0} end,
fn %{url: url, page: page} = resource ->
case fetch(url, page) do
{:ok, %{next_index: next_index} = result} ->
{[result], %{ resource | index: next_index }}
_ -> {:halt, resource}
end
end,
fn _ -> :ok end
)
In real cases the index will take the form of a cursor but the idea is the same: The resource can now be accessed as a stream to leverage every function that handles them.
Conclusion
The true power of Elixir enumerables comes from the combination of reusable utility modules, well-defined protocols and existing data types ready to be used. Armed with these tools you can take on most tasks easily and when the abstractions are not enough you can easily extend or build on top of them to suit your needs.
To conclude with this post here are some general recommendations to keep in mind when working with these abstractions.
Use
Enumby default: When in doubt start with this module and move toStreamsas necessary.Go for
Streamfor large data sets or resources that can be abstracted to emit values and will benefit from being treated as a stream.If still unsure and don't want to throw money at the problem then profile to understand where is/are potential bottlenecks. Finally, create alternative solutions and benchmark them.
Anti-pattern:
Using Streams from the start: Stream is not a silver bullet. Start simple unless you know the use case works better in general with Streams.
Use Streams for everything to prevent scaling issues: This is a form of early optimization that could also cause the opposite in some cases.
Reinvent the wheel by ignoring
Enumerable,Collectable,Stream,Enumand others: For simple solutions is fine to do so but if you find yourself reimplementing some of these functions for your data types then start thinking about how to implementEnumerableandCollectableto give superpowers to your key data structures.
I hope you liked this post and hope you subscribe to my newsletter 💌


